이 중에서 변경된 문서와 삭제된 문서들을 빨리알아내기 위한 문제가 freshness 문제다.
크롤러에 대해서 자세히 알고 싶다면 wikipedia의 크롤러(http://en.wikipedia.org/wiki/Web_crawler)페이지를 한번 읽어보길 바란다.
freshness를 보장하기 위해서는 재방문을 잘 진행해야하는데 이건은 매우 어려운 일이다.
왜냐하면 언제 문서가 update될지, 삭제될지는 작성하는 사람의 마음이기 때문이다.
위에서 언급했던 wikipedia 페이지에서 보면 Re-visit policy이라는 부분이 있다.
즉, 재방문의 정책을 어떻게 정하면 좋을지에 대한 설명이다.
Re-visit policy
The Web has a very dynamic nature, and crawling a fraction of the Web can take weeks or months. By the time a Web crawler has finished its crawl, many events could have happened, including creations, updates and deletions.
From the search engine's point of view, there is a cost associated with not detecting an event, and thus having an outdated copy of a resource. The most-used cost functions are freshness and age.[23]
Freshness: This is a binary measure that indicates whether the local copy is accurate or not. The freshness of a page p in the repository at time t is defined as:
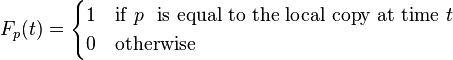
Age: This is a measure that indicates how outdated the local copy is. The age of a page p in the repository, at time t is defined as:
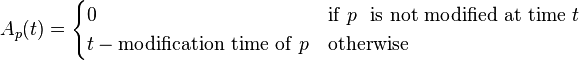
wikipedia에서는 아래와 같이 같은 간격으로 재방문하는 방법과 자주 바뀌는 페이지에 대해서 더 자주 방문하는 것에 대한 이야기가 나오는데 아이러니하게도 Uniform policy로 모든 문서들을 같은 간격으로 방문해 보는 것이 더 성능이 좋다고.... ;
Uniform policy: This involves re-visiting all pages in the collection with the same frequency, regardless of their rates of change.
Proportional policy: This involves re-visiting more often the pages that change more frequently. The visiting frequency is directly proportional to the (estimated) change frequency.
이유는 다음과 같은데 크롤러는 기본적으로 politeness policy를 지켜야하기 때문이다. 잠깐 설명하고 넘어가면 같은 site혹은 ip 단위에 너무 빠르게 접근하여 실제 서비스에 영향을 끼치지 말아야 한다는 것이다. 너무 빠른 crawling은 공격으로 간주될 수 있고 조그만 site의 경우는 서버가 down될 수도 있다. 아무튼 이 politeness를 지키기 위해서는 천천히 방문해야하고 천천히 방문하려면 Proportional policy에서 말하는 빠른 주기로 변경되는 문서(url)을 빨리 방문하기 위해 느리게 방문되는 문서를 방문할 기회를 모두 소진해 버릴 수 있다는 점이다.
즉, 느꼈겠지만 당연하게도 politeness를 위해 방문가능 횟수에는 제한이 있고 기회비용을 어떻게 쓰느냐가 중요한 과제이다. 재방문만을 위해 기회를 다쓴다면 새로 발견한 문서들은 어떻게 방문할 것인가? ;; ㅋ
이런 재방문을 위한 논문이 있는데 스탠포드의 조정후라는 사람이 쓴 논문이다. 아래 링크에서 pdf 버전을 볼 수 있다.
http://delivery.acm.org/10.1145/860000/857170/p256-cho.pdf?ip=111.91.137.45&CFID=38429943&CFTOKEN=99839736&__acm__=1315285766_988d177e0b0477aa349ae6b7c3480526
이 사람은 재미있게 구글 창업자들과 초창기에 같이 일했으며 crawling을 담당했다고 한다.
http://news.inews24.com/php/news_view.php?g_serial=228939&g_menu=021200
'Crawling' 카테고리의 다른 글
| html 본문 parsing (0) | 2012.05.09 |
|---|---|
| 크롤러 (crawler) (0) | 2011.12.08 |
| Url redirection (0) | 2011.08.12 |
| URL 파싱하기 (0) | 2011.08.09 |
| url에 program으로 접근되지 않을 때 (0) | 2011.07.05 |